Database relazionali
Si è potuto notare come una tabella di un database è strutturata in modo molto semplice: esistono i campi o attributi (colonne) e i record o tuple (righe). Le colonne sono definite in base al tipo di dato che contengono, le righe contengo i dati.
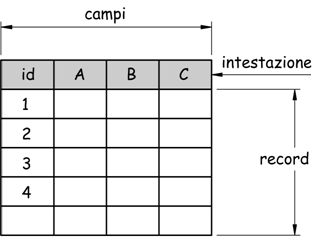
Si è visto, come in genere, una tabella sia caratterizzata da un campo
denominato chiave primaria (id).
La chiave primaria è un codice che identifica univocamente
ogni nuovo record che viene inserito che equivale a dire che non possono
esistere due record con la stessa chiave primaria.
Pensandoci bene, la nozione di chiave primaria, non è poi così astratta;
nel caso di anagrafiche di persone, dove possono essere frequenti i casi
di omonimia, la chiave primaria privilegiata è il codice fiscale (non
possono esserci due persone con lo stesso CF).
Qualsiasi database non è altro che un modello rappresentativo di una certa
realtà che interessa descrivere, si parla in particolare, di modello relazionale,
infatti fra la chiave primaria e gli altri campi della tabella esiste
una relazione 1 ad 1.
Nel caso dell'anagrafica di persone, assumendo CF come chiave primaria,
ad ogni persona corrisponde un solo codice fiscale e viceversa ( questo
è il caso di una relazione 1 a 1 ).
Bisogna ricordare che la chiave primaria di una tabella può anche
essere costituita soltanto da una combinazione di campi non primari, ad.
es. (Azienda+Città) o (Nome+Cognome+DataDiNascita).
Il problema più generale di creare una rappresentazione semplificata
di una certa realtà che possa essere manipolata (tramite inserimento o
modifica di dati) o interrogata (recuperando dati richiesti) si ottiene
attraverso la modellazione dei dati.
A partire dalla realtà considerata vengono individuati i dati ritenuti
significativi, viene definito uno schema concettuale preliminare ; da
questo schema (concettuale) vengono derivate le strutture logiche dei
dati (schema logico).
Lo schema concettuale è solitamente effettuato tramite il modello Entity-Relationship
(P.P.Chen 1976) col quale si analizza una realtà indipendentemente dalle
applicazioni che poi saranno usate per descriverla. In esso sono presenti:
L'entità: un oggetto concreto o astratto
considerato di interesse per la realtà che si vuole descrivere.
La relazione: che stabilisce come due
entità interagiscano fra loro.
Un esempio completo di schema ER è il seguente:
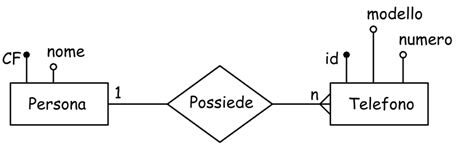
Sono presenti l'entità 'Persona' e l'entità 'Telefono'. E' presente la
relazione 'Possiede'. Le entità 'Persona' è caratterizzata da due attributi,
il CF o codice fiscale che fa da chiave primaria e il nome della persona.
Nell'entità 'Telefono' come attributi sono presenti la chiave primaria
id, il modello di telefono e il numero associato.
Si nota come la relazione 'Possiede' sia riconducibile al predicato verbale
dell'analisi grammaticale che sussiste fra un soggetto e un complemento
oggetto.
Importanti sono le indicazioni che si trovano agli estremi della relazione;
essi indicano il grado della relazione.
In questo caso sono di semplice lettura e affermano che fra le due entità
esiste una relazione 1 a n cioè una persona può possedere più telefoni.
Lo schema logico che viene derivato è il seguente
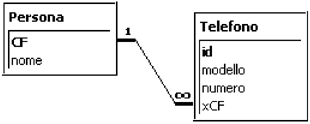
Ad ogni entità corrisponde una tabella; gli attributi diventano campi per le rispettive tabelle; deve essere,inoltre, introdotto un campo supplementare che faccia da chiave esterna (foreigner key FK) in questo caso xCF che sia riferito alla chiave primaria CF della tabella correlata 'Persona'.
In questo modo nel record descrittivo di ciascun telefono esistente verrà 'parcheggiata' una copia della chiave primaria (primary key PK) del possessore di quel telefono (in modo che sia possibile risalire ad esempio al nome del possessore di quel telefono) . Possiamo dunque affermare che se fra due entità esiste una relazione 1:n bisogna creare due tabelle. E' interessante ricordare come fra il codice fiscale e una persona esiste una relazione 1:1; in tal caso per descrivere grado di relazione è sufficiente una sola tabella.
A noi è venuto, peraltro, spontaneo inserire il CF col nome della persona nella stessa tabella 'Persona'. Quindi quando esiste una relazione 1:1 è sufficiente una sola tabella, quando la relazione è 1:n ci vogliono due tabelle con gli accorgimenti che abbiamo descritto fra PK ed FK.
Esiste l'eventualità che fra due entità ci sia una relazione n:n. Ad esempio, un corridore può partecipare a più gare e ad una gara possono partecipare più corridori.
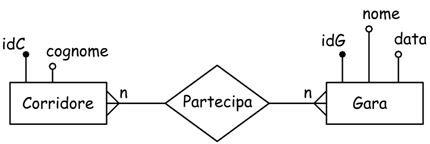
In questo caso la regola di derivazione per ottenere lo schema logico prevede l'uso di tre tabelle, cioè la relazione stessa diventa una tabella mentre cambia il verso delle relazioni:
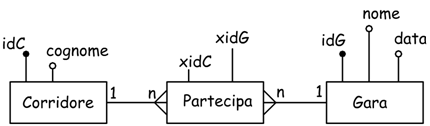
Si nota come la relazione molti-molti fra due tabelle diventa una coppia di relazioni uno-molti fra tre tabelle. Questa terza tabella deve necessariamente accogliere le FK (chiavi esterne) delle due tabelle principali; può essere dotata di una sua chiave primaria;può accogliere altri attributi (campi); non necessariamente deve mantenere lo stesso identificatore. Infatti uno schema equivalente al precedente può essere:
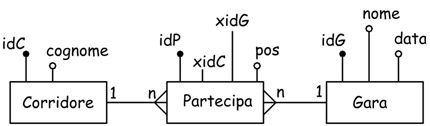
Si osserva come sia stato inserito in 'Partecipa' il campo supplementare pos per indicare la posizione raggiunta da un dato corridore, inoltre la stessa tabella è stata dotata di una chiave primaria.
In ogni caso bisogna ricordare che le chiavi esterne devono essere dello stesso tipo di dato delle chiavi primarie cui si riferiscono; cioè, se idC è numerico xidC deve essere numerico. Se idG è alfanumerico xidG deve essere alfanumerico. Lo schema logico che ne deriva è:
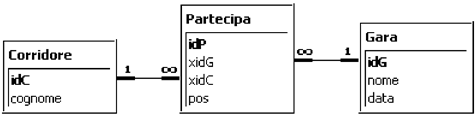
Quindi una particolare attenzione va data alle query di creazione; eccole tutte e tre:
CREATE TABLE Corridore (
idC COUNTER PRIMARY KEY,
cognome CHAR(20));
CREATE TABLE Gara(
idG COUNTER PRIMARY KEY,
nome CHAR(20),
data date );
CREATE TABLE Partecipa(
idP COUNTER PRIMARY KEY,
xidG INTEGER REFERENCES Gara(idG),
xidC INTEGER REFERENCES Corridore(idC),
pos INTEGER);
Se le chiavi esterne si riferiscono a delle chiavi primarie di tipo contatore (numerico autoincrementale) esse devono essere di tipo numerico (INTEGER). A seguito della parola chiave REFERENCES deve essere indicata il nome della tabella e fra parentesi la chiave primaria riferita.
Le tabelle possono essere riempite ora con dei valori di prova, ad esempio:
|
idC
|
cognome
|
|
1
|
Bianchi
|
|
2
|
Rossi
|
|
3
|
Verdi
|
|
4
|
Neri
|
|
5
|
Viola |
|
6
|
Ciano |
|
idG
|
nome
|
data
|
|
1
|
Milano-Sanremo
|
15/03/2000
|
|
2
|
Parigi-Rubaix
|
20/04/2000
|
|
3
|
Sestriere
|
20/06/2000
|
|
4
|
Alpe d'Huez |
25/06/2000
|
|
5
|
Zoncolan |
12/06/2000
|
|
6
|
Mont ventoux |
18/07/2000
|
|
7
|
Coppa Bernocchi |
25/08/2000
|
|
idP
|
xidG
|
xidC |
pos
|
|
1
|
1
|
1 |
5
|
|
2
|
3
|
1 |
10
|
|
3
|
5
|
1 |
7
|
|
4
|
2 | 2 |
12
|
|
5
|
4 | 2 |
16
|
|
6
|
6 | 2 |
20
|
|
7
|
1 | 3 |
7
|
|
8
|
7 | 3 |
1
|
|
9
|
2 | 4 |
6
|
|
10
|
6 | 4 |
1
|
|
11
|
3 | 5 |
5
|
|
12
|
5 | 5 |
3
|
|
13
|
7 | 6 |
1
|
Supponiamo di voler conoscere le posizioni in gara effettuate dal corridore 'Bianchi'
SELECT Partecipa.pos
FROM Corridore, Partecipa
WHERE Corridore.idC=Partecipa.xidC AND Corridore.cognome='Bianchi';
Se invece volessimo interrogare il database sulle posizioni conseguite da un corridore da noi scelto arbitrariamente:
SELECT Partecipa.pos
FROM Corridore, Partecipa
WHERE Corridore.idC=Partecipa.xidC AND Corridore.cognome=[corridore:];
Questa ci proporrebbe una finestra di dialogo di questo tipo:
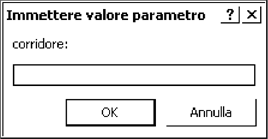
nella quale immettere il cognome del corridore (ma questo comando funziona solo con Access)
In queste query Sono coinvolte due tabelle: Corridore e Partecipa; si
nota come ambedue debbano essere incluse nella clausola FROM .
Per fare funzionare il tutto nella clausola WHERE bisogna aggiungere la
relazione fra le due tabelle data dall'istruzione:
WHERE Corridore.idC=Partecipa.xidC
Una tecnica alternativa consiste nell'uso del comando di JOIN:
SELECT Partecipa.pos
FROM Corridore INNER JOIN Partecipa ON Corridore.idC=Partecipa.xidC
WHERE Corridore.cognome='Verdi';
Questa seconda tecnica ci permette di non usare l'istruzione AND nel WHERE ma questa volta la relazione fra le tabelle coinvolte va definita nella clausola FROM secondo la sintassi illustrata.
Da notare come sia indifferente porre Corridore.idC=Partecipa.xidC
piuttosto che Partecipa.xidC= Corridore.idC.
Supponiamo di voler ricercare tutti i corridori che hanno fatto la gara del Mont ventoux riportandone la posizione. E' chiaro che stavolta sono coinvolte tutte e tre le tabelle, per cui:
SELECT Corridore.cognome, Partecipa.pos
FROM Corridore, Partecipa, Gara
WHERE Corridore.idC=Partecipa.xidC AND Partecipa.xidG=Gara.idG
AND Gara.nome='Mont ventoux';
Il risultato sarebbe
|
cognome
|
pos
|
|
Rossi
|
20
|
|
Neri
|
2
|
La versione con la clausola JOIN sarebbe:
SELECT Corridore.cognome, Partecipa.pos
FROM (Corridore INNER JOIN Partecipa ON Corridore.idC=Partecipa.xidC)
INNER JOIN Gara ON Partecipa.xidG=Gara.idG
WHERE Gara.nome='Mont ventoux';
Si possono applicare anche le funzioni di aggregazione viste nella lezione precedente; ipotizzando di voler vedere l'elenco dei corridori con la quantità di gare effettuate da ciascuno:
SELECT Corridore.cognome, COUNT(*) AS TOT
FROM Corridore,Partecipa
WHERE Corridore.idC=Partecipa.xidC GROUP BY Corridore.cognome;
|
cognome
|
TOT
|
|
Bianchi
|
3
|
|
Ciano
|
1
|
| Neri |
2
|
| Rossi |
3
|
| Verdi |
2
|
| Viola |
2
|
Notiamo come la clausola WHERE sia obbligatoria per definire la relazione fra le tabelle.
In questa versione
SELECT Corridore.cognome, COUNT(*) AS TOT
FROM Corridore INNER JOIN Partecipa ON Corridore.idC=Partecipa.xidC
GROUP BY Corridore.cognome;
non è necessario perché la relazione fra PK ed FK è già inclusa nella clausola FROM all'interno del comando di JOIN.
Ipotizziamo di voler avere l'elenco dei corridori che hanno partecipato alle gare di giugno con a fianco il numero di gare effettuate:
SELECT Corridore.cognome, COUNT(*) AS TOT
FROM Corridore, Partecipa, Gara
WHERE Corridore.idC=Partecipa.xidC AND Partecipa.xidG=Gara.idG
AND Gara.data<#07/01/2000# AND Gara.data>=#06/01/2000#
GROUP BY Corridore.cognome;
produce
|
cognome
|
TOT
|
|
Bianchi
|
2
|
| Rossi |
1
|
| Viola |
1
|
N.B.: le date vanno inserite nel formato indicato con notazione mm.gg.aaaa .
Riassumendo le cose dette sulle relazioni:
|
Domande
|
Si
|
No
|
| Può un codice fiscale appartenere a più persone ? |
X
|
|
| Può una persona avere più di un codice fiscale ? |
X
|
|
| Risultato= UNO a UNO: Creo 1 tabella |
|
Domande
|
Si
|
No
|
| Può una telefonata appartenere a più aziende? |
X
|
|
| Può un'azienda fare più telefonate? |
X
|
|
| Risultato= UNO a MOLTI: Creo 2 tabelle |
|
Domande
|
Si
|
No
|
| Può un allievo avere più insegnanti ? |
X
|
|
| Può un insegnante avere più allievi ? |
X
|
|
| Risultato= MOLTI a MOLTI: Creo 3 tabelle |
Un altro aspetto che caratterizza una buona progettazione di una base di dati è la normalizzazione delle tabelle.
Prima forma normale
Una tabella si trova in prima forma normale se tutte le sue colonne contengono valori atomici, il che significa che una colonna contiene solamente un elemento di informazione (come ad esempio il numero di telefono o il nome) e mai due o più informazioni dello stesso tipo (come per esempio due o più numeri di telefono o due o più nomi di persone)
|
PK
|
||||
| id | NomeSocietà | Indirizzo | Telefono | Fax |
| 1 | CIT | Piazza Diaz | 0473/78945 0434/75950 |
543343 |
| 2 | MEC | Via Mantù | 02/893445 | 355435 |
| 3 | OVS | Via Roma | 0187/98786 0321/873524 |
3456546 |
Questo è un esempio di una tabella da normalizzare. Infatti potrebbe
essere molto problematico individuare una data azienda in base al suo
numero di telefono, ecco una seconda soluzione:
|
PK
|
|||||
| id | NomeSocietà | Indirizzo | Telefono1 | Telefono2 | Fax |
| 1 | CIT | Piazza Diaz | 0473/78945 | 0434/75950 | 543343 |
| 2 | MEC | Via Mantù | 02/893445 | 355435 | |
| 3 | OVS | Via Roma | 0187/98786 | 0321/873524 | 3456546 |
Apparentemente la situazione è più ordinata ma comunque, non sappiamo a priori di quanti numeri di telefono può disporre una data azienda e questo limita le possibilità del nostro database. La soluzione è la seguente: due tabelle relazionate fra loro da una chiave esterna (FK o Forigner Key) .
|
PK
|
|||
| id | NomeSocietà | Indirizzo | Fax |
| 1 | CIT | Piazza Diaz | 543343 |
| 2 | MEC | Via Mantù | 355435 |
| 3 | OVS | Via Roma | 3456546 |
|
PK
|
FK | |
| idT | Telefono | xid |
| 1 | 0473/78945 | 1 |
| 2 | 0434/75950 | 1 |
| 3 | 02/893445 | 2 |
| 4 | 0187/98786 | 3 |
| 5 | 0321/873524 | 3 |
Seconda forma normale
Una tabella è in seconda forma normale se ogni attributo (campo) non facente parte della chiave primaria dipende funzionalmente in maniera irriducibile dall'intera chiave primaria.
|
PK=Nome+Cognome+Città
|
||||
| Nome | Cognome | Via | Città | Provincia |
| Carlo | Turri | Roma | Monza | MI |
| Giulia | Rovi | Sevi | Merano | BZ |
| Siria | Giusti | Golia | Monza | MI |
| Laura | Galli | Giuri | Monza | MI |
Vi è una dipendenza funzionale: ogni volta che si ripete il nome della
città, si ripete anche quello della provincia, Città=X, Provincia=Y, Y
dipende da X se ogni volta che si ripetono valori di X si ripetono quelli
di Y. Attenzione che la provincia dipende sono da una parte della chiave
primaria (Città) non dall'intera chiave (Nome+Cognome+Città).
Vi sono quindi, anomalie di aggiornamento e inconsistenza dei dati .
Se Turri trasloca a Merano devo ricordare di cambiare la Provincia altrimenti
risulta che Merano è in provincia di Milano sul record 1 e che Merano
è in provincia di Bolzano sul record 2. Inoltre, vi sono delle anomalie
di cancellazione : se cancelliamo il record 2 perdiamo l'informazione
che Merano è in provincia di BZ oltre che le informazioni di Giulia Rovi.
La soluzione a questi problemi è la seguente:
| PK=Nome+Cognome+Città | FK | ||
| Nome | Cognome | Via | Città |
| Carlo | Turri | Roma | Monza |
| Giulia | Rovi | Sevi | Merano |
| Siria | Giusti | Golia | Monza |
| Laura | Galli | Giuri | Monza |
| PK | |
| Città | Provincia |
| Monza | MI |
| Merano | BZ |
| Monza | MI |
| Monza | MI |
Si elimina dalla prima tabella il campo da normalizzare (Provincia) e si fa una seconda tabella che contiene tutti i campi (Citta e Provincia) che nella tabella originale davano origine a una dipendenza funzionale.
Terza forma normale
Una tabella si trova in terza forma normale se tutti gli attributi non chiave sono mutuamente indipendenti
| PK | |||
| lineaTel | tipo | ufficio | areaMq |
| 34 | fax | 2 | 200 |
| 43 | fax | 5 | 55 |
| 42 | telefono | 2 | 200 |
| 75 | telefono | 3 | 60 |
| 55 | telefono | 4 | 100 |
| 77 | fax | 2 | 200 |
| 57 | telefono | 3 | 60 |
| 56 | fax | 1 | 200 |
si ripetono 3 campi, ma solo ufficio e areaMq hanno una dipendenza funzionale. Anche in questo caso la soluzione è una suddivisione di tabelle.
| PK | FK | |
| lineaTel | tipo | ufficio |
| 34 | fax | 2 |
| 43 | fax | 5 |
| 42 | telefono | 2 |
| 75 | telefono | 3 |
| 55 | telefono | 4 |
| 77 | fax | 2 |
| 57 | telefono | 3 |
| 56 | fax | 1 |
| PK | |
| ufficio | areaMq |
| 1 | 200 |
| 2 | 200 |
| 3 | 60 |
| 4 | 100 |
| 5 | 55 |